Our research approach will leverage the advancement of machine learning to address challenges in optimization and control for complex systems such as large-scale multi-agent systems and systems operating in dynamic environments. Since multi-agent systems typically require coordination of multiple autonomous agents sharing coupling objectives and constraints, they often face scalability and real-time practicality challenges. Developing fast and distributed optimization methods is therefore a fundamental research focus. Control for systems operating in dynamic environments is further complicated by uncertainty from changing factors, from the environment or from human agents, which necessitates control designs capable of learning and adaptation.
Learning to Optimize, Control, and Adapt
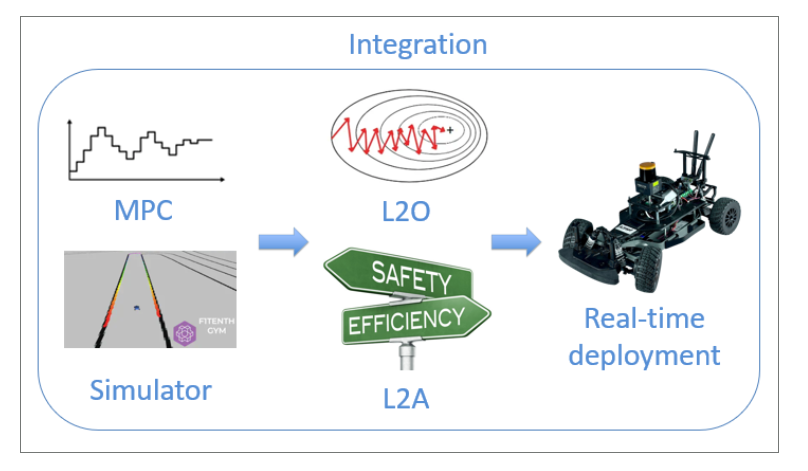
We plan to advance the state-of-the-art in machine learning for optimization and control with two directions: (1) learning-to-optimize/control for large-scale systems, and (2) learning-to-adapt control designs. Typical applications include cyber-physical human systems, robotic swarms in dynamic environments, and off-road autonomous driving.
A.1 Learning to Optimize/Control for Large-Scale Systems
Recently, there has been significant interest in leveraging machine learning to accelerate algorithms for optimization-based control, especially in mixed-integer optimization, where machine learning can be used to learn the optimal integer solution. Some recent methods rely on supervised learning [1, 2] or learning-to-optimize (L2O) [3]. However, most existing work has focused on optimization problems for single systems, while methods for multi-agent optimization have not received much attention. L2O in multi-agent settings poses several challenges. The problem formulation, including variables, constraints, and objective functions, depends on hyper-features of the multi-agent system such as the number of agents and the structure of coupling constraints. These hyper-features can vary across scenarios and may even change over time, making the learning task more complex. Collecting data for large-scale multi-agent systems is also often difficult and resource-intensive. A promising direction is to leverage Graph Neural Networks (GNNs), which can incorporate the graph-structured data of the system as input, capturing the dependencies between agents (nodes) and their interactions (edges). GNN-based models also offer potential scalability: they can be trained on data from small-scale systems and then applied to larger-scale systems.
Similarly, extending learning-to-control (L2C) to multi-agent systems is a promising direction. Consider differentiable MPC in end-to-end training [4], which learns explicit control policies based on differentiable programming and neural networks, i.e. u = π(x, ξ; ω). In the multi-agent setting, the local control policy for each agent may also depend on the features and states of other neighboring agents sharing coupling constraints. GNNs can incorporate these dependencies and learn the control policies for the agents. However, implementing GNNs in a distributed or decentralized manner for real-time control is challenging, as it requires inter-agent communication to exchange hidden features, which becomes intractable as the number of GNN layers or their dimensions increase. L2C with distributed/decentralized implementation that allows efficient communication and computation therefore remains an open research area.
Expected outcomes: (1) a scalable and efficient L2O framework for solving large-scale optimization problems, particularly challenging cases such as nonlinear or mixed-integer programs; and (2) an L2C framework for multi-agent systems that enables efficient computation and communication for real-time deployment.
A.2 Learning to Adapt Controllers (LINC — Learning Introspective Control)
In many control applications, systems are required to operate in dynamic environments, under changing conditions or tasks, for example, autonomous driving with varying road conditions, or autonomous racing with different racing strategies of opponents. A key research direction is therefore developing the learning-to-adapt (L2A) framework, in which we learn to adapt controllers such as differentiable MPC in a sim-to-real manner. L2A shares the same idea with control-oriented meta-learning [6] or meta reinforcement learning [7], but L2A with differentiable MPC can leverage MPC's strengths in guaranteeing safety through constraints and efficiency through long-horizon planning.
A potential approach is to treat the MPC problem as a policy and learn to adapt its parameters, such as objective weights or constraint coefficients, using differentiable programming or RL. In our proposed L2A framework, we aim at finding the optimal adaptation strategy for MPC given different contextual variables θ that capture changing conditions or task specifications. We approximate this optimal adaptation strategy by a neural network γ = ψ(θ). We can additionally consider an explicit neural control policy within differentiable MPC of the form u = π(x, γ; ω), training both the neural policy and the adaptation strategy end-to-end. The main challenge is making the MPC layer differentiable and obtaining gradients with respect to MPC parameters, which is particularly difficult under hard constraints.
Expected outcome: an L2A framework that enables differentiable MPC to be adaptable and generalizable in dynamic environments, with the potential to outperform existing control-oriented meta-learning approaches.
Sampling-based MPC for Process Control

Industrial applications like boilers, distillation columns, and fuel pumps require accurate and robust process control capable of adhering to strict constraints. MPC has proven to be a reliable strategy for advanced process control (APC), but usually relies on an optimization solver requiring that dynamics, constraints, and objectives adhere to specific solver-compatible structures. Model Predictive Path Integral (MPPI) control extends the standard MPC formulation to nonlinear and stochastic systems and solves the resulting optimization problem through sampling, overcoming the need for solver-compliant structures. This flexibility enables MPPI to support richer models while maintaining the model-based optimal control framework. It inherently addresses MPC's limitations while enabling new capabilities:
Stochasticity by construction — MPPI is better suited for handling system noise and disturbances compared to optimization-based MPC, which requires constraint tightening or chance constraints. Nonlinear dynamics — saturations, rate limits, hysteresis, and discontinuous responses are handled by simulating trajectories under exact dynamic constraints, bypassing linearization compromises. MPPI can also use high-fidelity simulators such as UniSim as an internal model. Learning-ready — MPPI rollouts can incorporate learned predictive models, value functions from RL, and uncertainty-aware surrogates such as Gaussian processes for adaptive risk mitigation. Safety-critical supervision — MPPI can serve as a "safety filter" for human operators or pre-trained learned policies, attenuating unsafe actions while preserving performant trajectories rather than binary rejection.
The AI4IA Center will identify target MPC problems where Honeywell engineers face challenges, to demonstrate how MPPI can learn and adapt to changing dynamics and conditions and iteratively improve processes.
B.1 Safe Information-Theoretic Learning MPC (SIT-LMPC)
Industrial automation of processes like chemical reactions, heat exchange, and fluid transport often involve complex nonlinear dynamics and demand control strategies that guarantee robustness, safety, and high performance in uncertain environments. The control of these processes often involves repetitive tasks for which many previous demonstrations or trajectories exist. We propose SIT-LMPC: an iterative, information-theoretic MPC framework for constrained infinite-horizon optimal control of discrete-time nonlinear stochastic systems. An adaptive penalty method ensures safety while balancing optimality by solving for optimal penalty parameters online. Trajectories from previous iterations train a value function using normalizing flows, enabling richer uncertainty modeling compared to Gaussian priors. SIT-LMPC is designed for highly parallel GPU execution and iteratively improves performance while robustly satisfying system constraints.
B.2 Failure-Aware Information-Theoretic Adaptive Learning MPC (FAITAL-MPC)
Model mismatch can degrade control performance, leading to overshoot or constraint violation. We propose formulating a pair of sets: the unsafe-set — states for which some control input can steer the system into constraint violation — and the failure-set — states for which all control inputs result in constraint violation. These sets can be annotated from failing demonstrations, human annotation, or reachability analysis. Avoiding them yields non-convex constraints that traditional MPC handles only via conservative convex approximations; a failure-aware MPPI controller handles them directly. By progressively updating these sets, controllers learn from failing trajectories and human demonstrations to reduce future failure likelihood, even under model mismatch.
B.3 Combined Bayesian Active Learning and Bayesian Optimization (BALBO)
An alternative to failure-aware control for handling model-mismatch is simultaneous learning and control (SLC), which actively learns the dynamics while optimizing control performance. We propose formulating this as a multi-objective optimization problem: minimize model uncertainty by finding the maximally exciting trajectories (Bayesian Active Learning), while maximizing performance by finding the minimum cost trajectory (Bayesian Optimization). To scale to high-dimensional systems, we rely on Multi-Objective Regionalized Bayesian Optimization (MORBO), which also allows incorporating safety constraints. The resulting controller optimizes for a given task while simultaneously learning a minimum-entropy model. To enable real-time deployment on uncertain systems, we formulate BALBO as a finite-horizon optimization solved with MPPI.
B.4 Geometry-aware MPC by Learning Non-Planar Dynamics
This thrust develops multi-terrain vehicle controllers for autonomous machines in logistics, hospitality, and off-road autonomy. Mobile robot dynamics are often modelled for 2D environments, where inclines and bumps are handled by onboard compensating controllers, limiting the domain these robots can operate in. We propose learning the dynamics using a library of models, each for a predefined set of surfaces (e.g. incline, bank, flat). Online, the current dynamics are identified by weighting this library to best fit the current conditions, either based on current geometry (3D orientation) or learned via a discriminator model. Because the learned dynamics are highly nonlinear and potentially non-differentiable, we rely on MPPI for control. The resulting controller handles robots on 3D surfaces through this weighted model combination, deployable in a few-shot manner for rapid adaptation to new unseen geometries.
Multi-Agent Teams for Cooperation and Competition
The goal of this thrust is to (1) develop the theory for collaborative and cooperative multi-agent teams in adversarial competitions; and (2) design and evaluate algorithms for intent recognition, distributed intelligence, and adversarial training for multiagent systems.
C.1 Adversarial Training: Interpretable Team Skill Discovery in Multi-agent Games
This effort focuses on aligning agents to work effectively in collaboration within a team, improving mission success. Our proposed approach enhances multi-agent reinforcement learning (MARL) by leveraging skill discovery, particularly in defense applications involving large-scale multiagent coordination. Unlike existing methods which suffer from poor interpretability and lack diversity enforcement, our method introduces team skill-conditioned RL policies based on Social Influence (SI). By mapping agent interactions into a 2D skill space where each vector represents unique team-level behaviors, a central controller can assign skill vectors to optimize cooperative strategies. This approach significantly improves coordination in complex multi-agent environments. We validate this in Capture-the-Flag simulation scenarios where teams navigate obstacles and adversarial interactions to retrieve the opponent's flag.
C.2 Mission Specification Language for Multi-Agent Teams and Competitions
The safe planning and control of multi-agent systems for complex missions with spatial, temporal and reactive constraints is becoming an area of utmost importance. We will develop a Signal Temporal Logic (STL) based mission specification language to generate dynamically feasible multi-agent missions that are tractable and generate simulations for centralized and distributed settings. Given a mission expressed in STL, our controller maximizes robustness to generate trajectories for the multiagent systems satisfying the STL specification in continuous-time. We will show that the constraints on our optimization guarantee that these trajectories can be tracked nearly perfectly by lower-level controllers.
C.3 Learning-based Safe Predefined-Time Multiagent Pursuit-Evasion Games
A multiagent pursuit-evasion game in cluttered environments is a challenging problem where timely strategic decision-making is paramount. Existing learning-enabled game-theoretic control frameworks lack predefined-time convergence guarantees, are not scalable, and are computationally intensive. To overcome these limitations, we propose learning-based safe predefined-time multiagent pursuit-evasion games. We address the cooperative pursuit of multiagent players by deploying a team of pursuers in a shared obstacle-rich and unknown environment, in the context of games such as soccer, autonomous racing, and capture the flag. Our contributions are: a scalable algorithm for team assignment; an online data-driven algorithm for rapid adaptation to unknown environments; a safely predefined-time convergent game-theoretic framework enabling pursuers to intercept evaders while maintaining safety; and learning algorithms for synthesizing optimal distributed pursuing/evading strategies. Our frameworks are provably correct based on rigorous mathematical analysis validated via multiagent simulations.
C.4 STL-guided Stein Variational Path Integral Optimization (STL-SVPIO)
Signal Temporal Logic (STL) enables formal specification of complex spatiotemporal constraints for robotic task planning, but synthesizing long-horizon continuous control trajectories from complex STL specifications is fundamentally challenging. Existing solver-based methods (e.g. MILP) suffer from exponential scaling, while sampling methods (e.g. MPPI) struggle with sparse, long-horizon costs. We introduce STL-SVPIO, which reframes STL as a globally informative, differentiable reward-shaping mechanism. By leveraging Stein Variational Gradient Descent and differentiable physics engines, STL-SVPIO transports a mutually repulsive swarm of control particles toward high-robustness regions, transforming sparse logical satisfaction into tractable variational inference. STL-SVPIO significantly outperforms existing methods in both robustness and efficiency, and solves complex long-horizon tasks including multi-agent coordination with synchronization and queuing where baselines either fail or become computationally intractable.
AI Coaching Game

A core barrier to effectively using AI for education is that today's AI systems are often designed to prevent people from making mistakes so aggressively that they lose the chance to learn from and reflect on failures [23]. This ultimately makes human–AI interaction in education open-loop: when AI corrects mistakes frequently, users are protected in the moment but may become over-reliant on AI and never acquire the necessary skills to operate independently. Our proposed AI Coaching Game is a strategic decision-making framework for AI-assisted education designed to address the key question: how should an AI help a person learn a difficult skill involving physical insights (e.g., writing programs to race a car, fly a drone, or navigate a legged robot) without accidentally blocking that learning by over-assisting?
The Coaching Game models AI-based education as a partially-observable stochastic dynamic game (POSG) [24]: at every moment, the AI coach chooses how to help based on what the human is doing and what the coach thinks the human will learn as a consequence. The coach's "success" is not simply the learner's high performance under heavy assistance, it is whether the human becomes independent. To achieve this, the AI coach's reward explicitly reflects long-term learning outcomes rather than short-term task success. Extending prior work on assistance games [25–27] and belief-space games [28, 29], we develop a new theory showing that this POSG reduces to a POMDP. We then design an algorithmic framework to approximately solve the resulting problem and obtain a Coaching Game control policy using multi-agent RL. The resulting policy is defined over the joint space of physical states and belief states encoding the AI's uncertainty about the learner's skill level.
A major challenge in coaching is that perceived human performance does not directly reveal underlying skill. This is amplified in shared control, where observed outcomes conflate human and AI contributions. Building on knowledge tracing techniques [30, 31], we develop a novel Assistance-Conditioned Bayesian Knowledge Tracing (ABKT) model that embeds assistance-awareness and task context directly into the real-time inference process. Unlike standard BKT models that assume fixed model parameters, ABKT makes them context-dependent by training a neural network that maps AI assistive actions and contextual inputs to the parameters of the knowledge tracing model. This allows ABKT to disentangle true skill mastery from temporary success due to assistance, while dynamically adapting to the learner's evolving skill level. Combining the Coaching Game policy with ABKT enables a structured learning loop: the AI adapts its assistance level, resets on mistakes, explains failure causes, suggests improvements, demonstrates the right move, and asks the human to practice, shifting from a passive "guardian" to an active mentor.
Physics-Informed Digital Twins
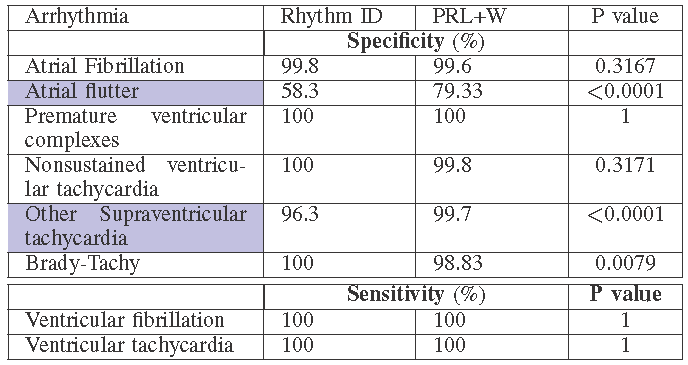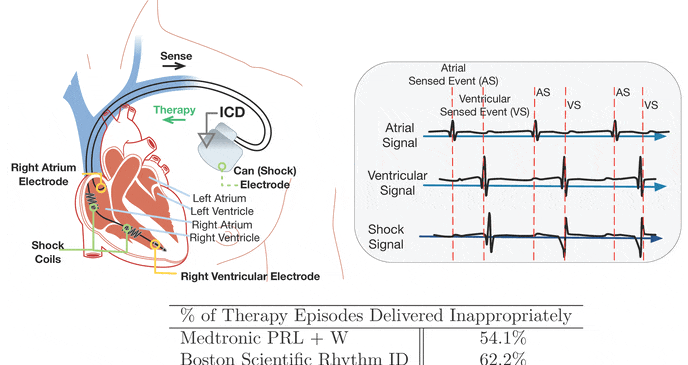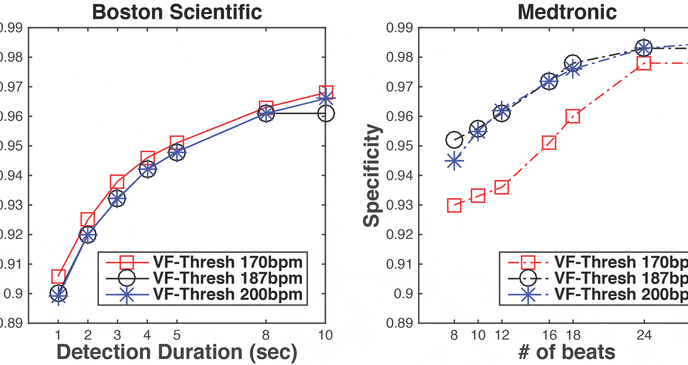
Digital twins — virtual models of physical systems updated with real-time data — are revolutionizing fields from aerospace to healthcare. This thrust develops Physics-Informed Cardiac Digital Twins for Modeling and Therapy of Atrial Fibrillation (AF). Affecting nearly 60 million people globally, AF is treated primarily with catheter ablation, which remains hampered by excessive procedure times (2–4 hours), high recurrence rates (45% within 12 months), and disappointing first-procedure success rates (only 50% for persistent AF). These limitations stem from a fundamental challenge: physicians must navigate complex cardiac structures using only sparse local measurements, essentially "searching in the dark" for arrhythmia sources.
The core mathematical challenge is creating accurate, real-time predictive models from limited observations that generalize across varied anatomies. Current approaches face three critical barriers: (1) inability to transfer knowledge across different patient geometries, (2) lack of reliable uncertainty quantification essential for clinical decisions, and (3) failure to maintain physical consistency during adaptation. Our digital twin framework addresses these through geometry-aware neural operators, advanced uncertainty quantification, and physics-constrained transfer learning.
Key innovations include: (1) geometry-aware neural operators that transfer knowledge across diverse anatomies, reducing per-patient data requirements by up to 80%; (2) scalable epistemic uncertainty quantification methods providing real-time confidence estimates with sub-10ms inference times; and (3) physics-constrained transfer learning ensuring physiological consistency while enabling rapid adaptation to new patients with minimal fine-tuning. Our preliminary work has already demonstrated the ability to replicate various arrhythmias with 85–96% accuracy using deterministic heart models, providing a strong foundation for these innovations.
Symbiotic Design for Cyber-Physical Systems
The goal of this thrust is to mine previous designs of complex cyber-physical systems, such as turbines, diesel engines, and process control plants, to generate new designs given new requirements. Think of this as autocomplete for model-based design, where a 50%-complete design is completed to 80% with an 80% chance of success. This thrust, entitled the Systemic Generative Engineering Framework (SGEF), proposes a modular, open-source AI toolchain to: (i) construct, (ii) compose, and (iii) explore vast design spaces that arise in cyber-physical systems.
The design space construction AI ingests previous designs and heterogeneous data, using machine learning and knowledge graphs (KG) to capture explicit and implicit knowledge (e.g. mappings of requirements to functions, functions to components, components to configurations). The design composition AI generatively synthesizes design alternatives and assists engineers with automatic generation of evaluation pipelines. The design space exploration AI enables the inverse design of complex CPS driven by target performance metrics and constraints, finding unintuitive and novel design alternatives that are very difficult for human experts to discover.
SGEF will revolutionize the CPS design process across industries including automobile and aircraft manufacturers, electrical energy producers, smart buildings, and robot manufacturers. We anticipate improvement of over 10× in design cycle times, with significant cost savings from accelerated design and reuse of implicit knowledge from past designs. In contrast to approaches relying on formal verification after the fact, SGEF leverages rapid ML evaluation to synthesize designs that are "correct-by-construction", fundamentally altering the paradigm from trial-and-error in familiar design spaces to AI-driven iterations that go beyond known design space.
AI Safety Through Uncertainty Quantification and Guardrails
Owners and operators of physical assets are often cautious of deploying potentially unsafe algorithms on their expensive physical plant. Safe control methods like Control Barrier Functions [15] are designed to be safe by construction, but their requisite assumptions are often limiting. Other recent approaches like Reinforcement Learning prioritize performance [4] and leave safety as an afterthought [16]. Our approaches use physics constraints to provide guardrails and insight for AI systems, paired with Conformal Prediction to enable understanding of how incorrect predictions may be. Appropriate incorporation of physics constraints can reduce the computational and data burden of training high-performance, trustworthy Agentic Intelligence systems.
G.1 Physics-Constrained Neural Networks
Physics-Constrained Neural Networks (PCNNs) embed physics or dynamics rules directly in the network architecture, providing hard-constraints, guarantees that the output will obey a preset set of dynamical equations, unlike PINNs which only enforce constraints softly. These expert-provided models enhance trustworthiness. PCNNs enable us to solve for any component of a dynamical system given the others: given the dynamics and a distribution of states, we can learn control inputs for optimal control in small robots and networked systems [17] and motion prediction [18]. Given the states and controls, we can learn system dynamics [19]. We will identify Honeywell process control use cases to apply and demonstrate the power of PCNNs as safety guardrails for Agentic Intelligence.
G.2 Conformal Prediction: Quantifying Uncertainty
Conformal Prediction (CP) is a statistical framework for quantifying uncertainty [20] that builds statements of the form: "With high probability, the ground truth is X away from my prediction", with statistical guarantees. CP only requires a calibration dataset exchangeable with the test dataset, and the non-conformity score can be any function. It is also distribution-free, making no assumptions on the classifier or input distributions. CP enables uncertainty quantification without retraining models (unlike Bayesian Neural Networks [22]) or assuming input distributions (unlike Uncertainty Propagation [21]). Our prior work [17, 18, 19] has focused on enabling efficient CP non-conformity scores using domain expertise and optimization, and extending CP to scenarios with off-policy RL. We will enable CP for high-dimensional systems and adapt CP using human intent.
G.3 Guarding Critical Behavioral Assumptions
Given the behavioral models used in our verification techniques, there is a need to guard the assumptions of these models to understand when the validity of verification procedures is in jeopardy. This includes out-of-distribution (OOD) detection schemes for machine learning or implementation conformance techniques for traditional algorithms, validating value transformation properties (e.g. accumulator bit size for physical quantities) and availability properties (e.g. tolerance to failures). Guarding model assumptions is key in two respects: detecting when new adaptation is needed, and designing protection mechanisms to prevent reaching unsafe states while agents continue to adapt.
G.4 Preserving Trust in a Dynamic Complex Agentic System
Large industrial automation systems integrate many components developed by multiple teams. The safety of these systems must be established not only to prevent critical accidents but also to prevent significant economic loss. The flexibility required by agentic systems — reassembling controllers and recomposing system-wide safety guarantees with respect to controller stability, hardware failure reliability, and non-smooth mode changes — stresses traditional assumptions. For instance, while a dynamical system or NN computation is considered instantaneous in models, in reality it takes time that can interfere with sensor-to-actuation delay and critical simultaneous-interaction assumptions. An aircraft landing incident in Taiwan in 2020 [11] illustrates the consequences: the bouncing of the plane led replicated controllers to disagree about whether the plane was airborne or on the ground, causing a triple computer failure.
Verifying the assumptions of different models is key to establishing trust in these complex systems. Our preliminary work created analysis contracts defining assume/guarantee interfaces between different behavioral models and their analyses [14]. Our Symbolic Assurance Refinement framework [13] supports incremental specification of key properties and their behavioral models, creating a constraint satisfaction problem using first-order logic in SMT to verify the formal argumentation structure, validate contracts as design detail accumulates, and determine whether properties can be validated. This framework was used to evaluate solutions to the Taiwan flight incident design problem [12]. New challenges arise with the dynamic nature of agentic systems, requiring argumentation assembled from contracts for models of components and behavioral techniques.
References
- A. Cauligi et al., "CoCo: Online mixed-integer control via supervised learning," IEEE RA-L, 7(2):1447–1454, 2021.
- A. Cauligi et al., "PRISM: Recurrent neural networks and presolve methods for fast mixed-integer optimal control," L4DC, PMLR, 2022.
- B. Tang, E. B. Khalil, J. Drgona, "Learning to optimize for mixed-integer nonlinear programming," arXiv:2410.11061, 2024.
- J. Drgona et al., "Differentiable predictive control," Journal of Process Control, 116:80–92, 2022.
- E. Tolstaya et al., "Learning decentralized controllers for robot swarms with graph neural networks," CoRL, PMLR, 2020.
- S. M. Richards et al., "Control-oriented meta-learning," IJRR, 42(10):777–797, 2023.
- D. G. McClement et al., "Meta-RL for the tuning of PI controllers," Journal of Process Control, 118:139–152, 2022.
- A. Romero et al., "Actor-critic model predictive control," arXiv:2306.09852, 2024.
- M. Raissi, P. Perdikaris, G. E. Karniadakis, "Physics-informed neural networks," J. Comput. Phys., 378:686–707, 2019.
- G. E. Karniadakis et al., "Physics-informed machine learning," Nature Reviews Physics, 3(6):422–440, 2021.
- Taiwan Transportation Safety Board, China Airlines Flight CI202 Occurrence, TTSB-AOR-21-09-001, 2021.
- D. de Niz et al., "Flight Incident Analysis Through Symbolic Argumentation," DASC, 2024.
- D. de Niz, L. Wrage, "Symbolic Refinement for CPS," ACM SIGAda Ada Letters, 43(1):88–93, 2023.
- I. Ruchkin et al., "Contract-based integration of cyber-physical analyses," EMSOFT, 2014.
- A. D. Ames et al., "Control Barrier Functions: Theory and Applications," ECC, 2019.
- P. Hamadanian et al., "How Reinforcement Learning Systems Fail and What to Do about It," EuroMLSys, 2022.
- R. Tumu et al., "Differentiable Predictive Control for Large-Scale Urban Road Networks," arXiv:2406.10433, 2024.
- R. Tumu et al., "Physics Constrained Motion Prediction with Uncertainty Quantification," IEEE IV, 2023.
- R. Tumu et al., "Zero-Shot Context Identification through Clustering and Foundation Modeling for Friction Estimation," 2025.
- A. N. Angelopoulos, S. Bates, "A Gentle Introduction to Conformal Prediction," arXiv:2107.07511, 2022.
- L. V. Jospin et al., "Hands-On Bayesian Neural Networks," IEEE Comput. Intell. Mag., 17(2):29–48, 2022.
- B. Peherstorfer, K. Willcox, M. Gunzburger, "Survey of Multifidelity Methods," SIAM Rev., 60(3):550–591, 2018.
- J. Metcalfe, "Learning from Errors," Annu. Rev. Psychol., 68:465–489, 2017.
- E. A. Hansen, D. S. Bernstein, S. Zilberstein, "Dynamic programming for partially observable stochastic games," AAAI, 2004.
- D. Hadfield-Menell et al., "Cooperative inverse reinforcement learning," NeurIPS, 2016.
- J. F. Fisac et al., "Pragmatic-Pedagogic Value Alignment," in Robotics Research, Springer, 2020.
- D. Malik et al., "An Efficient, Generalized Bellman Update for Cooperative IRL," ICML, PMLR, 2018.
- A. Bajcsy et al., "Analyzing Human Models that Adapt Online," ICRA, 2021.
- H. Hu et al., "Deception Game: Closing the Safety-Learning Loop in Interactive Robot Autonomy," CoRL, PMLR, 2023.
- A. T. Corbett, J. R. Anderson, "Knowledge tracing," User Model. User-Adapt. Interact., 4(4):253–278, 1994.
- C. Piech et al., "Deep Knowledge Tracing," NeurIPS, 2015.
About the Director
Rahul Mangharam is Professor of Electrical & Systems Engineering, and Computer & Information Science at the University of Pennsylvania. He builds safe autonomous systems at the intersection of formal methods, machine learning, and controls, applied to safety-critical autonomous vehicles, urban air mobility, life-critical medical devices, and AI Co-Designers for complex systems. He is the Penn Director for the U.S. Department of Transportation's $20M Safety21 National UTC (2023–2029) and Director of the Autoware Center of Excellence for Autonomous Driving, a consortium of 80+ companies and universities.
Rahul received the 2016 U.S. Presidential Early Career Award (PECASE) from President Obama for his work on Life-Critical Systems, the 2016 DOE CleanTech Prize (Regional), the 2014 IEEE Benjamin Franklin Key Award, the 2013 NSF CAREER Award, and the 2012 Intel Early Faculty Career Award, and was selected by the National Academy of Engineering for the 2012 and 2017 U.S. Frontiers of Engineering. He has won several ACM and IEEE best paper awards in Cyber-Physical Systems, controls, machine learning, and education. He leads the RoboRacer.AI Autonomous Racing Community across 90+ universities worldwide.